Farewell Photoshop? Met de nieuwe AI van Google kunt u de afbeeldingen bewerken door te vragen.

Multimodale output opent nieuwe mogelijkheden
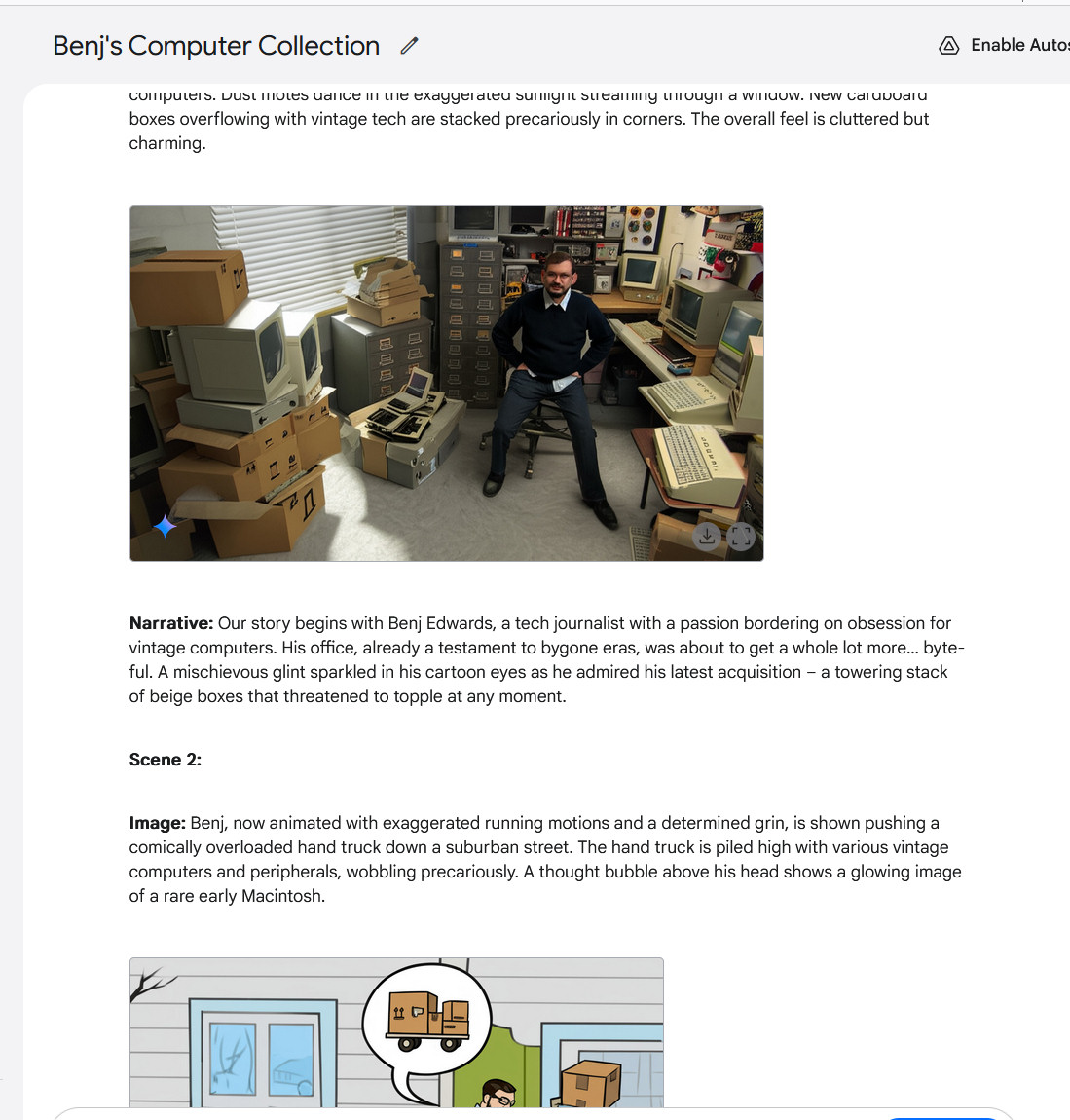
De echte multimodale output legt aantrekkelijke nieuwe mogelijkheden op chatbots bloot. Gemi 2.0 Flash Interactive Graphical Games kunnen bijvoorbeeld verhalen spelen of verhalen maken met seriële afbeeldingen, karakter behouden en de continuïteit bepalen in meerdere afbeeldingen. Het is verre van perfect tot perfect, maar de voortzetting van het personage is een nieuwe kracht onder AI -assistenten. We hebben het geprobeerd en het was behoorlijk weefsel – vooral toen het een foto maakte van foto’s die we vanuit een andere invalshoek hebben geleverd.
Gemi 2.0 Flash, om een multi-picture verhaal te maken met deel 1.
Google / Benz Edwards
Let op de alternatieve hoek van de originele foto om een multi-picture verhaal te maken met Gemi 2.0 Flash, deel 2.
Google / Benz Edwards
Let op de alternatieve hoek van de originele foto om een multi-picture verhaal te maken met Gemi 2.0 Flash, deel 2.
Google / Benz Edwards
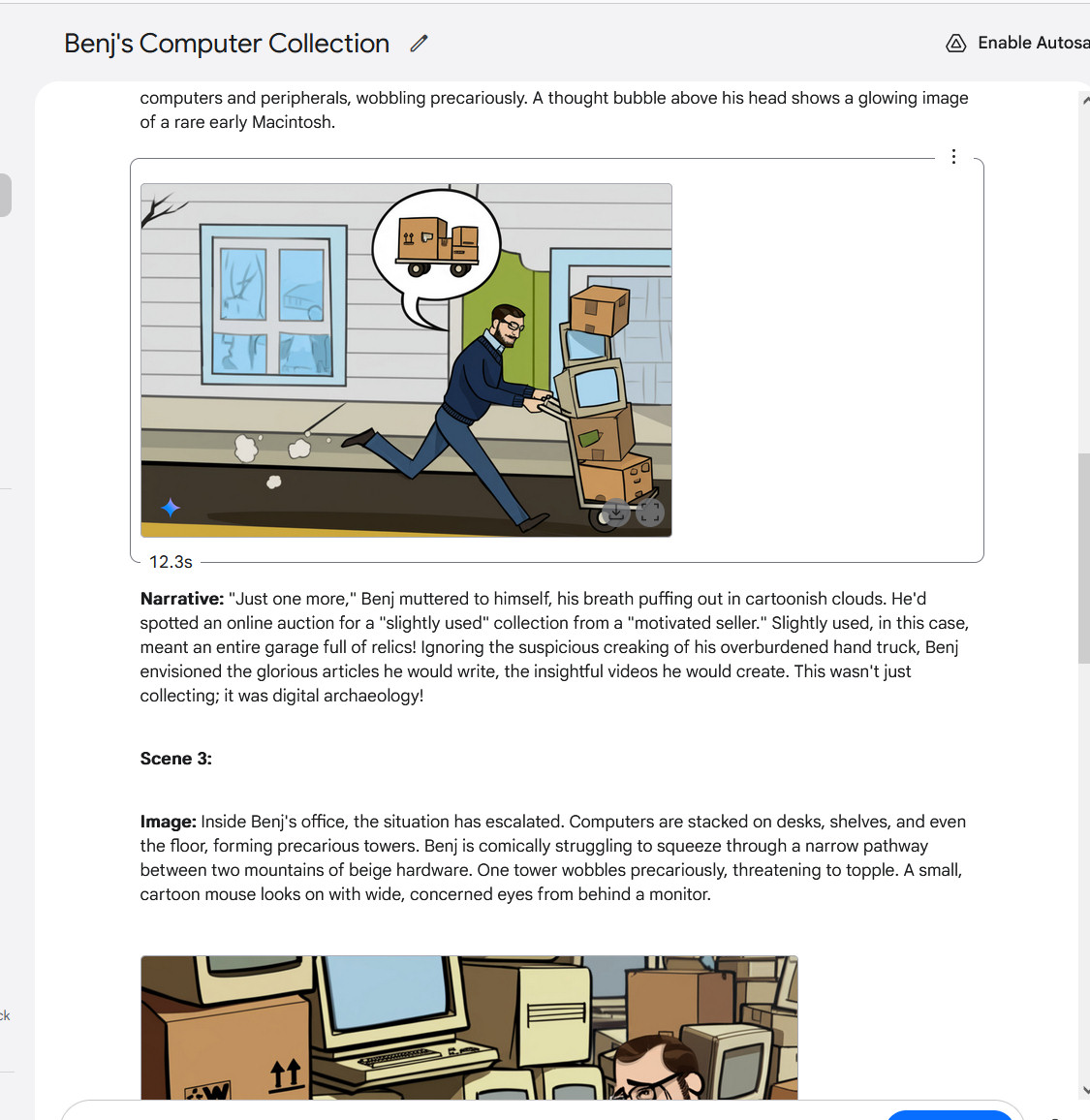
Gemi 2.0 Flash, om een multi-picture verhaal te maken met deel 3.
Google / Benz Edwards
Gemi 2.0 Flash, om een multi-picture verhaal te maken met deel 3.
Google / Benz Edwards
Let op de alternatieve hoek van de originele foto om een multi-picture verhaal te maken met Gemi 2.0 Flash, deel 2.
Google / Benz Edwards
Gemi 2.0 Flash, om een multi-picture verhaal te maken met deel 3.
Google / Benz Edwards
De tekst presenteert nog een potentiële kracht van het renderingmodel. Google heeft beweerd dat interne criteria hebben aangetoond dat Jemi 2.0 Flash laat zien dat bij het maken van teksten beter presteert dan “topcompetitieve modellen”, het mogelijk maakt om inhoud te maken met geïntegreerde lessen. Uit onze ervaring waren de resultaten niet zo opwindend, maar ze waren duidelijk.
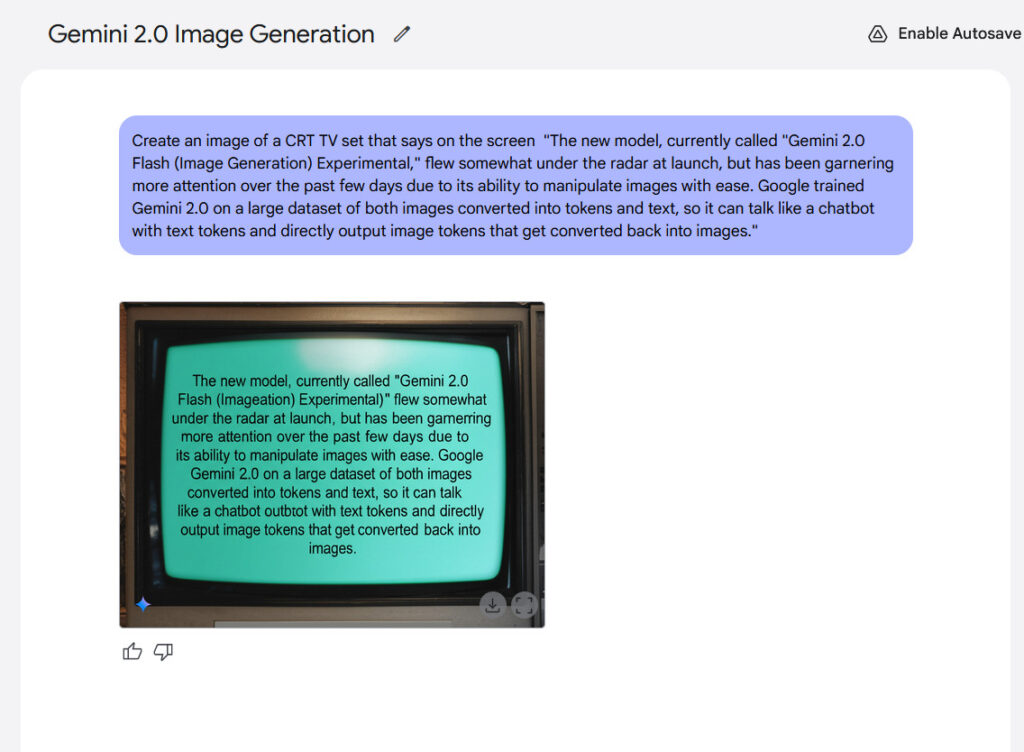
Een voorbeeld van het weergeven van de in-imagetekst gegenereerd met Flash of Gemini 2.0.
Credit: Google / Ars Technica
Ondanks de defecten tot nu toe bij de Flash of Gemi 2.0, lijkt de opkomst van een echte multimodale beelduitgang een belangrijk moment in de AI -geschiedenis omdat de technologie blijft verbeteren. Als je je de toekomst voorstelt, zeg dan over 10 jaar vanaf nu, waar voldoende complex AI-model elk type media kan maken in realtime gelezen, afbeelding, audio, video, 3D-graphics, 3D-print fysieke objecten en interactieve ervaringen zijn eigenlijk één HoldecDe zaak is echter zonder transcript.
Echt geretourneerd, het is nog steeds “vroege dagen” voor de multimodale beelduitvoer en Google herkent het. Vergeet niet dat Flash 2.0 het doel is om een klein AI -model te zijn dat snel en goedkoper is, dus het absorbeerde niet de hele breedte van internet. Alle informatie kost veel ruimte om de parameter te berekenen en meer parameters berekenen de betekenis van meer parameters. In plaats daarvan heeft Google Gemi 2.0 -flits getraind door een curate datasaat te voeren met waarschijnlijk doelsynthetische gegevens. Als gevolg hiervan ‘weet’ het model niet alles wat visueel is over de wereld en Google zelf zegt dat trainingsgegevens “breed en gewoon, perfect of compleet” zijn.
Dit is precies de manier om een chique manier te zeggen waarop de uitvoerkwaliteit van de afbeelding niet perfect is – Yeat. Trainingstechnieken hebben veel ruimte om de toekomst te verbeteren om meer visuele “kennis” op te nemen zoals van tevoren en berekeningsdruppels. Als het proces zoiets wordt dat we hebben gezien met op expansie gebaseerde AI-beeldgeneratoren zoals stabiele expansie, midjorn en flux, kan de multimodale beelduitvoerkwaliteit binnenkort in korte tijd verbeteren. Volledige vloeibare media maken zich klaar voor de realiteit.




